






Visual data
Images can be scanned from paper, painted or drawn using software, or captured from the camera on a cellphone or tablet. Video capture is provided routinely on smartphones, tablets, and many computers. Images come in many different shapes, sizes, textures, colors, shadings, and levels of detail. Different processing requirements require different forms for image data. All these differences make it difficult to define a single universal format that can be used for images in the way that the standard alphanumeric codes are used for text. Instead, the image will be formatted according to processing, display, application, storage, communication, and user requirements.
Images used within the computer fall into two distinct categories:
- bitmap images
- object images
Images such as photographs and paintings that are characterized by continuous variations in shading, color, shape, and texture are bitmap images. To maintain and reproduce the detail of these images, it is necessary to represent and store each individual point within the image. The Graphics Interchange Format (GIF), Portable Network Graphics (PNG), and Joint Photographic Experts Group (JPEG) formats commonly used on the Web are all examples of bitmap image formats. The BMP format is a bitmap image format developed by Microsoft and currently used by Windows Paint and Macintosh Paintbrush programs.
Images that are made up of graphical shapes such as lines and curves that can be defined geometrically belong to other group. The shapes themselves may be quite complex. Many computer experts refer to these shapes as graphical objects. For these images, it is sufficient to store geometrical information about each object and the relative position of each object in the image. These images are object images. They are also known as vector images, because the image is often made up of straight line segments called vectors. ![]()
![]() Bitmap images are also commonly referred to as raster graphics or raster images.
Bitmap images are also commonly referred to as raster graphics or raster images.
The actual data value representing a pixel could be as simple as one bit, for an image that is black and white (0 for black, 1 for white, for example) or quite complex. Each pixel in a high-quality color image, for example, might consist of many bytes of data: a byte for red, a byte for green, and a byte for blue, with additional bytes for other characteristics such as transparency and color correction. The storage and processing of bitmap images frequently requires a large amount of memory and the processing of large arrays of data. A single-color high-definition picture containing 1,080 rows of 1,920 pixels each (1920 × 1080 image), with a separate byte to store each of three colors for each pixel, would require approximately 6 MB of storage. An alternative representation method that is useful for display purposes when the number of different colors is small reduces the memory requirements by storing a code for each pixel, rather than the actual color values. The code for each pixel is translated into actual color values using a color translation table known as a palette that is stored as part of the image metadata.
Reducing the size of each pixel improves the possible resolution, or detail level, of the representation by increasing the number of pixels per inch used to represent a given area of the image. It also reduces the “stepping” effects seen on diagonal lines. Increasing the range of values available to describe each pixel increases the number of different gray levels or colors available, which improves the overall accuracy of the colors or gray tones in the image.
Object images are made up of simple elements like straight lines, curved lines (known as Bezier curves), circles and arcs of circles, ovals, and the like. Each of these elements can be defined mathematically by a small number of parameters. For example, a circle requires only three parameters, specifically, the X and Y coordinates locating the circle in the image, plus the radius of the circle. A straight line needs the X and Y coordinates of its end points, or alternatively, by its starting point, length, and direction. Object images are created using drawing software, rather than paint software. Because objects are defined mathematically, they can be easily moved around, scaled, and rotated without losing their shape and identity. Object images have many advantages over bitmap images. They require far less storage space. They can be manipulated easily, without losing their identity. In contrast, if a bitmap image is reduced in size and reenlarged, the detail of the image is permanently lost. In graphically based systems, it is necessary to distinguish between characters and the object image-based representations of characters, known as glyphs.
Video images
A video camera producing full screen 1920 × 1080 pixel true-color images at a frame rate of thirty frames per second, for example, will generate 1920 pixels × 1080 pixels × 3 bytes of color/image × 30 frames per second = 178 MB of data per second! A one-minute film clip would consume 10.4 GB of storage. There are a number of possible solutions: reduce the size of the image, limit the number of colors, or reduce the frame rate. Each of these options has obvious drawbacks. If we consider video as a sequence of bitmap image frames, we quickly realize that the images do not usually change much from frame to frame; furthermore, most of the changes occur in only a small part of the image. Even in a fast-moving sport like football, the only object that moves much in the 1/30 second between frames is the ball; the players move relatively little in that short time span. The video format is determined by a codec, or encoder/decoder algorithm. There are a number of different standards in use. The best-known codec standards are MPEG-2, MPEG-4, and H.264. Microsoft Windows Media Video Format and Ogg Theora are popular proprietary codecs. The MPEG-2 and MPEG-4 formats store and transmit real-time video that produces movie quality images, with the video data compressed to 10–60 MB or less of data per minute, even for high-definition images. This reduction in data is critical for streaming video.
Audio data
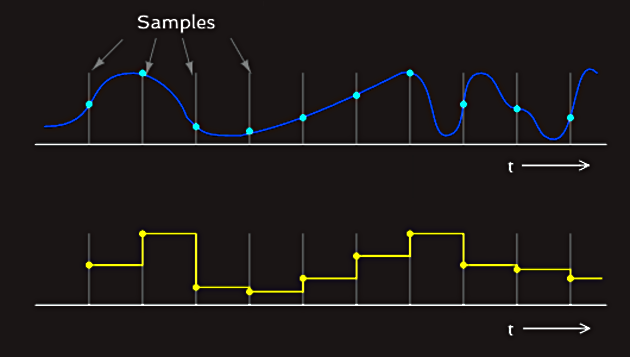
Since the original sound wave is analog in nature, it is necessary to convert it to digital form for use in the computer. The analog waveform is sampled electronically at regular time intervals. Each time a sample is taken, the amplitude of the sample is measured by an electronic circuit that converts the analog value to a binary equivalent. The circuit that performs this function is known as an A-to-D converter. The largest possible sample, which represents the positive peak of the loudest possible sound, is set to the maximum positive binary number being used, and the most negative peak is set to the largest negative number. Binary 0 falls in the middle. We have shown an example of analog to digital conversion of an audio waveform on the figure below: 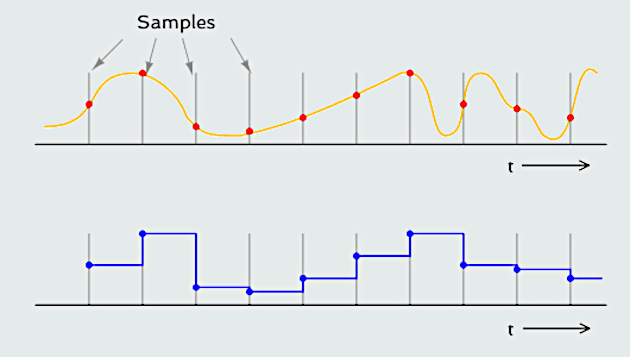
 There are a number of different codecs and file formats for storing audio waveforms, each with its own features, advantages, and disadvantages.
There are a number of different codecs and file formats for storing audio waveforms, each with its own features, advantages, and disadvantages.
Data compression
The volume of multimedia data, particularly video, but also sound and even high-resolution still images, often makes it impossible or impractical to store, transmit, and manipulate the data in its normal form. Instead, it is desirable or, in many cases, necessary to compress the data. This is particularly true for video clips, real-time streaming video with sound, lengthy sound clips, and images that are to be transmitted across the Internet through modem connections.
There are many different data compression algorithms, but all fall into one of two categories, lossless or lossy. A lossless algorithm compresses the data in such a way that the application of a matching inverse algorithm restores the compressed data exactly to its original form. Lossy data compression algorithms operate on the assumption that the user can accept a certain amount of data degradation as a trade-off for the savings in a critical resource such as storage requirements or data transmission time. Only lossless data compression is acceptable for files where the original data must be retained, including text files, program files, and numerical data files, but lossy data compression is frequently acceptable in multimedia applications.
For example, suppose that we have the following string of data:
0 5 5 7 3 2 0 0 0 0 1 4 7 3 2 9 1 0 0 0 0 0 6 6 8 2 7 3 2 7 3 2
There are two simple steps we could take to reduce this string.
First, we could reduce the amount of data by counting the strings of consecutive 0s, and maintaining the count instead of the string. The character is reproduced once, followed by its count:
0 1 5 5 7 3 2 0 4 1 4 7 3 2 9 1 0 5 6 6 8 2 7 3 2 7 3 2
As a second step, the algorithm attempts to identify larger sequences within the string. These can be replaced with a single, identifiable value. In the example string, the sequence “7 3 2” occurs repeatedly. Let us replace each instance of the sequence with the special character “Z”:
0 1 5 5 Z 0 3 1 4 Z 9 1 0 5 6 6 8 2 Z Z
Application of these two steps has reduced the sample string by more than 35 percent. A separate attachment to the data would identify the replacements that were made, so that the original data can be restored losslessly. For the example, the attachment would indicate that 0s were replaced by a single 0 followed by their count and the sequences “7 3 2” were replaced by “Z”. There are also many variations on the methods shown in the example...
Page description languages
A page description language is a language that describes the layout of objects on a displayed or printed page. Page description languages incorporate various types of objects in various data formats, including, usually, text, object images, and bitmap images. The page description language provides a means to position the various items on the page. Most page description languages also provide the capability to extend the language to include new data formats and new objects using language stubs called plug-ins. Most audio and video extensions fall into this category. Page description languages combine the characteristics of various specific data formats together with data, indicating the position on the page to create data formats that can be used for display and printing layouts.
Internally, all data, regardless of use, are stored as binary numbers. Instructions in the computer support interpretation of these numbers as characters, integers, pointers, and, in many cases, floating point numbers. Computers use internal circuits to work with numbers, performing various operations such as addition, subtraction, multiplication, and division. These circuits are designed to process binary data, which consists of 0s and 1s.
Binary Representation: Computers use a binary number system, which represents numbers using only two digits: 0 and 1. Each digit in a binary number is called a bit (short for binary digit). For example, the decimal number 5 is represented as 101 in binary, where the rightmost bit represents 2^0, the next bit represents 2^1, and so on.
Logic Gates: The fundamental building blocks of digital circuits are logic gates. Logic gates are electronic devices that perform basic logical operations on binary inputs to produce binary outputs. Common logic gates include AND, OR, NOT, and XOR gates. These gates are combined in various ways to perform complex operations.
Adders: Adders are circuits used to perform addition operations. They take two binary numbers as input and produce the sum as output. Adders can be designed to handle different numbers of bits, such as 4-bit, 8-bit, or 16-bit adders. Larger adders are built by combining multiple smaller adders.
Subtractors: Subtractors are circuits used to perform subtraction operations. They take two binary numbers as input and produce the difference as output. Subtractors can be implemented using adders and additional logic gates to handle the borrowing process.
Multipliers: Multipliers are circuits used to perform multiplication operations. They take two binary numbers as input and produce the product as output. Multipliers use a combination of addition and shifting operations to perform multiplication efficiently.
Dividers: Dividers are circuits used to perform division operations. They take two binary numbers as input and produce the quotient and remainder as output. Division is a more complex operation compared to addition, subtraction, and multiplication, and dividers require more complex circuitry.
Registers and Memory: Internal circuits in computers also include registers and memory components. Registers are temporary storage units used to hold data during processing. Memory components, such as RAM (Random Access Memory), store data and instructions for the computer to access and manipulate.
It's important to note that modern computers use integrated circuits (ICs) to implement these internal circuits. ICs are small electronic devices made up of multiple interconnected components, such as transistors, resistors, and capacitors, etched onto a semiconductor material. These ICs are designed to perform specific functions and are combined to create complex circuits within a computer.
Computers work with input data by receiving signals or data from various input devices and processing them to produce output. Input devices allow users to provide data, instructions, or commands to the computer system. Computers can accept input from a variety of peripheral devices, each designed to accommodate specific types of data. Some common examples of input devices include keyboards, mice, touchscreens, scanners, microphones, cameras, and sensors. Input devices capture and convert user input into a format that the computer can understand. For example, when we type on a keyboard, the keystrokes are converted into electrical signals that the computer interprets as characters. Similarly, a scanner converts physical documents or images into digital data that can be processed by the computer. Once the computer receives the input data, it processes it using the central processing unit (CPU) and associated memory. The CPU executes the instructions provided by the input data, performing calculations, making decisions, and executing tasks based on the input. Input data is often used to interact with software applications. For example, we can input commands or data into a word processing software to create a document, or input values into a spreadsheet software to perform calculations. The software processes the input data and produces the desired output. Input data can come from various sources and serve different purposes. For instance, factory workers may input data by punching in on a time clock, musicians may input data using musical instruments connected to a computer, and users may input data through web-based forms using HTML input fields. So, computers work with input data by receiving signals or data from input devices, converting them into a format the computer can understand, processing the input using the CPU, and interacting with software applications to produce the desired output.