






CPUs execute ordered sets of instructions, from one instruction to the next. A CPU takes an input clock signal, and a clock pulse acts as a signal to the CPU to transition between states. It’s an oversimplification to think that a CPU executes exactly one instruction per clock cycle. Some instructions take multiple cycles to complete. Also, modern CPUs use an approach called pipelining to divide instructions into smaller steps so that portions of multiple instructions can be run in parallel by a single processor. For example, one instruction can be fetched while another is decoded and yet another is executed. Modern CPUs have clock speeds measured in gigahertz (GHz), so let's say 2 GHz CPU has a clock that oscillates at 2 billion cycles per second! 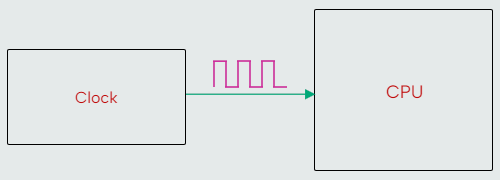
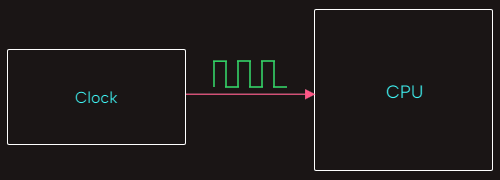 Increasing the frequency of the clock allows a CPU to perform more instructions per second. Unfortunately, we can’t just run a CPU at an arbitrarily high clock rate. CPUs have a practical upper limit on their input clock frequency, and pushing a CPU beyond that limit leads to excessive heat generation. Also, the CPU’s logic gates may not be able to keep up, causing unexpected errors and crashes. For many years, the computer industry saw steady increases in the upper limit of clock rates for CPUs. This clock rate increase was largely due to regular improvements in manufacturing processes that led to increased transistor density, which allowed to have CPUs with higher clock rates but roughly the same power consumption.
Increasing the frequency of the clock allows a CPU to perform more instructions per second. Unfortunately, we can’t just run a CPU at an arbitrarily high clock rate. CPUs have a practical upper limit on their input clock frequency, and pushing a CPU beyond that limit leads to excessive heat generation. Also, the CPU’s logic gates may not be able to keep up, causing unexpected errors and crashes. For many years, the computer industry saw steady increases in the upper limit of clock rates for CPUs. This clock rate increase was largely due to regular improvements in manufacturing processes that led to increased transistor density, which allowed to have CPUs with higher clock rates but roughly the same power consumption.
With clock rates stagnant, the processor industry turned to a new approach for getting more work out of a CPU. Rather than focusing on increasing clock frequency, CPU design began to focus on execution of multiple instructions in parallel. The idea of a multicore CPU was introduced, a CPU with multiple processing units called cores. A CPU core is effectively an independent processor that resides alongside other independent processors in a single CPU package. 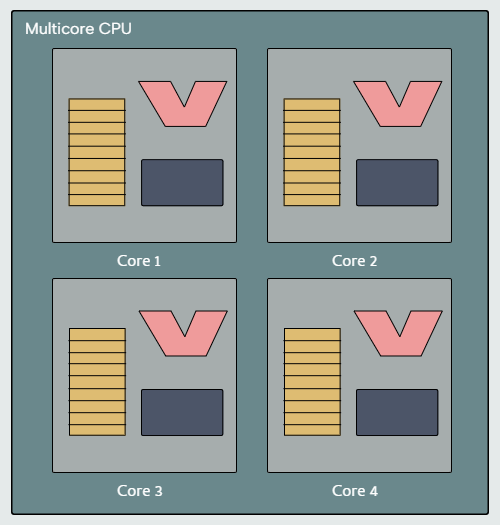
 Parallelism and pipelining are both techniques used to improve processor performance, but they are quite different in their approach.
Parallelism and pipelining are both techniques used to improve processor performance, but they are quite different in their approach.
Parallelism in processors, also known as parallel processing, refers to the ability of a computational system to execute multiple tasks or processes simultaneously. In a parallel computing environment, multiple processors or processing units are used to execute tasks in parallel, which can significantly increase overall system performance. Parallelism focuses on executing multiple tasks simultaneously by using multiple processors or processing units.
Pipelining, on the other hand, is a technique that divides a task into several smaller tasks and arranges them in a sequence. Each smaller task is executed in a dedicated segment of the processor known as a pipeline stage. A processor using pipelining works on several smaller tasks belonging to different instructions at the same time, with each task occupying one pipeline stage. Pipelining concentrates on breaking down a task into smaller tasks and executing them in a sequence through different stages of the processor pipeline.
Both techniques aim to improve processor performance, but parallelism leverages multiple processors, while pipelining makes the most of a single processor by keeping it constantly occupied with tasks. Going further, we can mention here hyperthreading, also.
Hyperthreading, pipelining and parallelism are all techniques employed in processors to improve performance and efficiency. Hyperthreading allows a single processor core to handle multiple threads simultaneously by duplicating certain sections of the processor core, such as the register file and instruction pointers, while sharing other resources like the execution units and caches. Pipelining divides tasks into smaller subtasks, with each subtask being executed in a dedicated pipeline stage. The processor works on several smaller tasks belonging to different instructions at the same time, with each task occupying one pipeline stage. Parallelism involves executing multiple tasks simultaneously by leveraging multiple processors or processing units. Each processor handles a separate task or part of a task concurrently, resulting in faster processing times for certain types of workloads.
Hyperthreading works within a single processor core, enabling it to handle multiple threads simultaneously. Pipelining operates within a single processor, focusing on efficiently executing instructions within a single thread. Parallelism operates at the system level, utilizing multiple processors or processing units to execute tasks concurrently.
These techniques can be combined to maximize processor performance and efficiency. For example, a system with multiple processors can use hyperthreading and pipelining within each processor to further enhance performance.
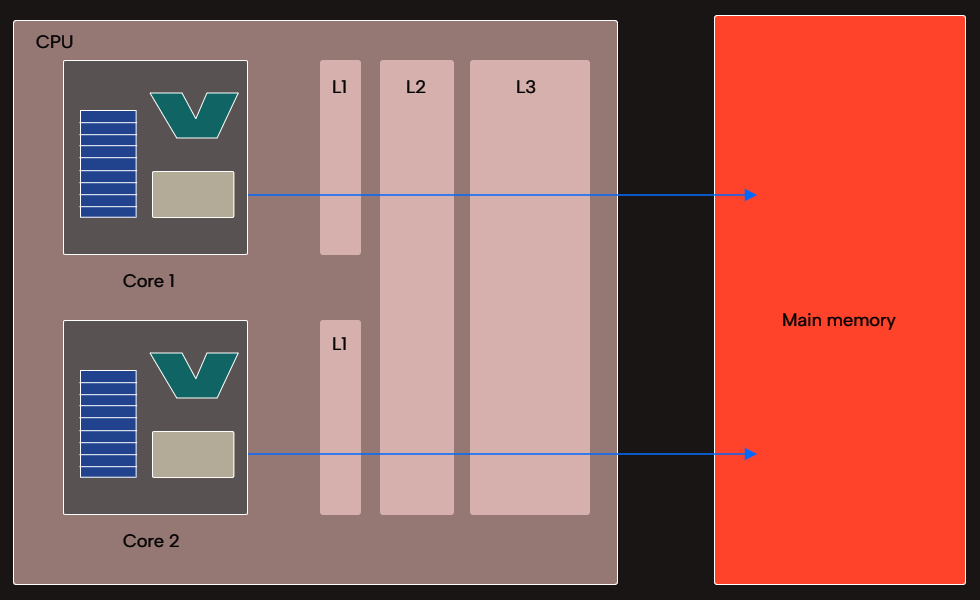
We know by now that CPUs load data from main memory into registers for processing and then store that data back from registers to memory for later use. It turns out that programs tend to access the same memory locations over and over. But going back to main memory multiple times to access the same data is inefficient! To avoid this inefficiency, a small amount of memory resides within the CPU that holds a copy of data frequently accessed from main memory. This memory is known as a CPU cache. It’s common for processors to have multiple cache levels, often three. We refer to these cache levels as L1 cache (smallest but fastest), L2 cache (slower and larger), and L3 cache (slower and larger, still). The processor checks the cache to see if data it wishes to access is there. If so, the processor can speed things up by reading or writing to the cache rather than to main memory. When needed data is not in the cache, the processor can move that data into cache once it has been read from main memory. 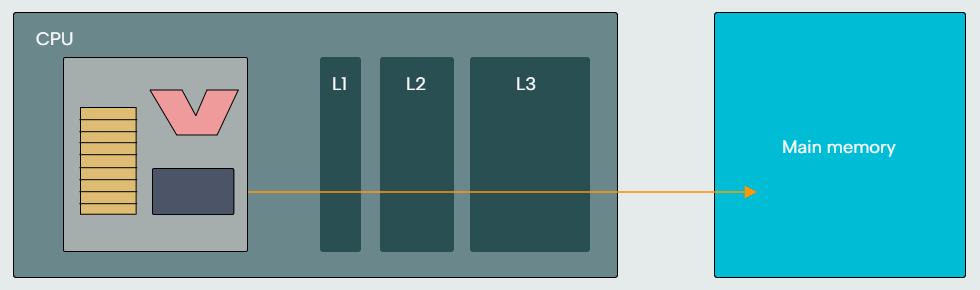
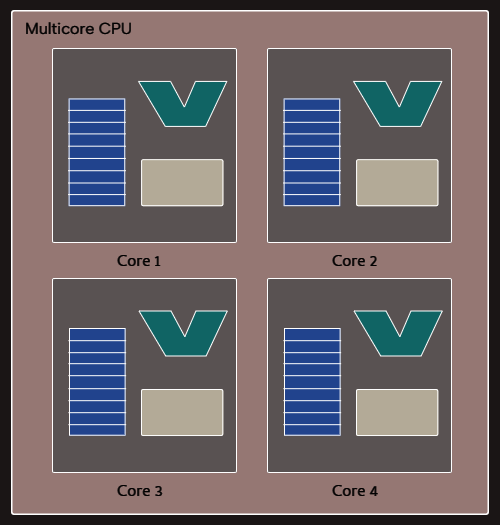
 In multicore CPUs, some caches are specific to each core, whereas others are shared among the cores. For example, each core may have its own L1 cache, whereas the L2 and L3 caches are shared.
In multicore CPUs, some caches are specific to each core, whereas others are shared among the cores. For example, each core may have its own L1 cache, whereas the L2 and L3 caches are shared. 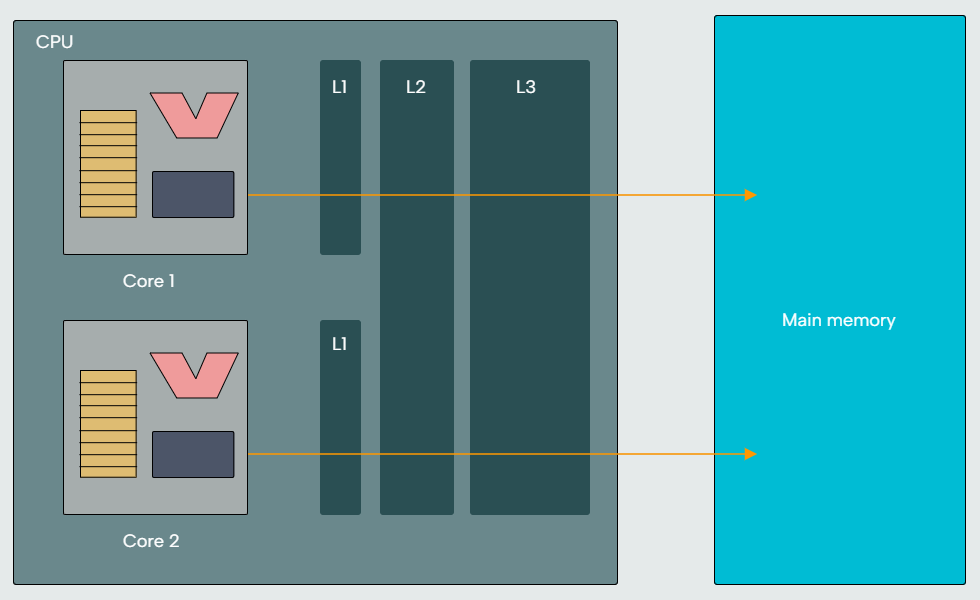
Secondary storage and I/O
These two elements fill in two gaps, respectively. The first gap is that both memory and CPUs are volatile; they lose state when power is removed. The second gap is that a computer with only memory and a processor has no way of interacting with the outside world.
Secondary storage is nonvolatile and therefore remembers data even when the system is powered down. Unlike RAM, secondary storage is not directly addressable by the CPU. When a computer is powered on, the operating system loads from secondary storage into main memory; any applications that are set to run at startup also load. After startup, when an application is launched, program code loads from secondary storage into main memory. The same goes for any user data (documents, music, settings, and so on) stored locally. In modern computing devices, hard disk drives and solid-state drives are the most common secondary storage devices. A hard disk drive (HDD) stores data using magnetism on a rapidly spinning platter, whereas a solid-state drive (SSD) stores data using electrical charges in nonvolatile memory cells. They are faster, quieter, and more resistant to mechanical failure, since SSDs have no moving parts.