






Human interaction with a computer requires going through I/O. Computer-to-computer interaction also requires going through I/O, often in the form of a computer network, such as the internet. 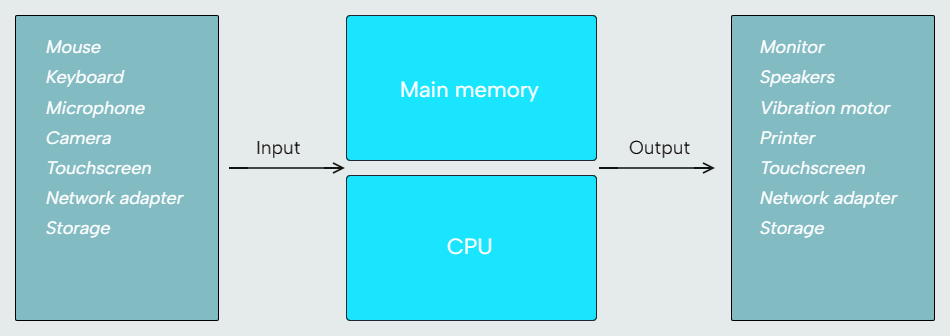
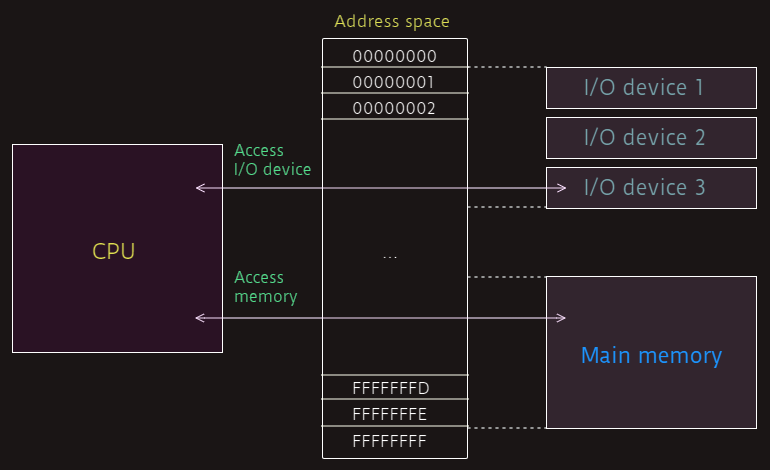
 A computer can have a wide variety of I/O devices attached to it, and the CPU needs a standard way to communicate with any such device. Addresses in physical address space don’t always refer to bytes of memory; they can also refer to an I/O device. When physical address space is mapped to an I/O device, the CPU can communicate with that device just by reading or writing to its assigned memory address(es); and this is called memory-mapped I/O (MMIO). However, some CPU families, notably x86, do include special instructions for accessing I/O devices. When computers use this approach, rather than mapping I/O devices to a physical memory address, devices are assigned an I/O port. A port is like a memory address, but instead of referring to a location in memory, the port number refers to an I/O device. Accessing I/O devices through a separate port address space is known as port-mapped I/O (PMIO). I/O ports and memory-mapped I/O addresses generally refer to a device controller rather than directly to data stored on the device.
A computer can have a wide variety of I/O devices attached to it, and the CPU needs a standard way to communicate with any such device. Addresses in physical address space don’t always refer to bytes of memory; they can also refer to an I/O device. When physical address space is mapped to an I/O device, the CPU can communicate with that device just by reading or writing to its assigned memory address(es); and this is called memory-mapped I/O (MMIO). However, some CPU families, notably x86, do include special instructions for accessing I/O devices. When computers use this approach, rather than mapping I/O devices to a physical memory address, devices are assigned an I/O port. A port is like a memory address, but instead of referring to a location in memory, the port number refers to an I/O device. Accessing I/O devices through a separate port address space is known as port-mapped I/O (PMIO). I/O ports and memory-mapped I/O addresses generally refer to a device controller rather than directly to data stored on the device. 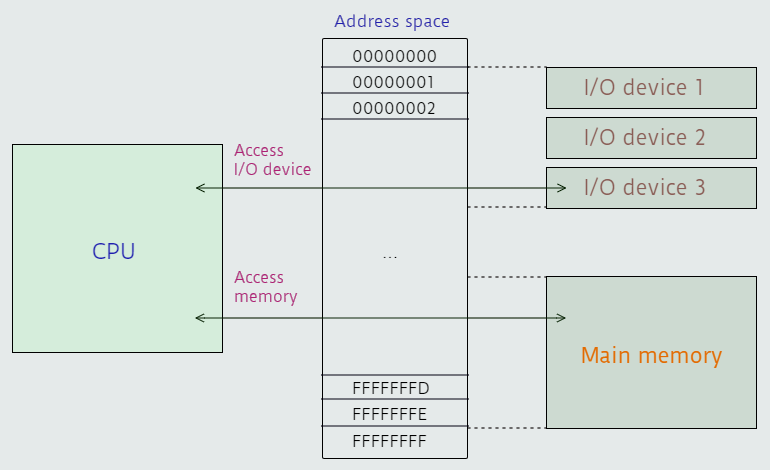
 A bus is a hardware communication system used by computer components. There are three common bus types used in communication between the CPU, memory, and I/O devices. An address bus acts as a selector for the memory address that the CPU wishes to access. The data bus transmits a value read from memory or a value to be written to memory. Finally, a control bus manages the operations happening over the other two buses.
A bus is a hardware communication system used by computer components. There are three common bus types used in communication between the CPU, memory, and I/O devices. An address bus acts as a selector for the memory address that the CPU wishes to access. The data bus transmits a value read from memory or a value to be written to memory. Finally, a control bus manages the operations happening over the other two buses.
Data Formats
In the past, most business data processing took the form of text and numbers. Today, multimedia, consisting of images and sounds in the form of video conferencing, PowerPoint presentations, VoIP telephony, Web advertising, YouTube, smartphone-based news clips and photos, and more is of at least equal importance. Since data within the computer is limited to binary numbers, it is almost always necessary to convert our words, numbers, images, and sounds into a different form in order to store and process them in the computer.
At some point, original data, whether character, image, sound, or some other form, must be brought initially into the computer and converted into an appropriate computer representation so that it can be processed, stored, and used within the computer system.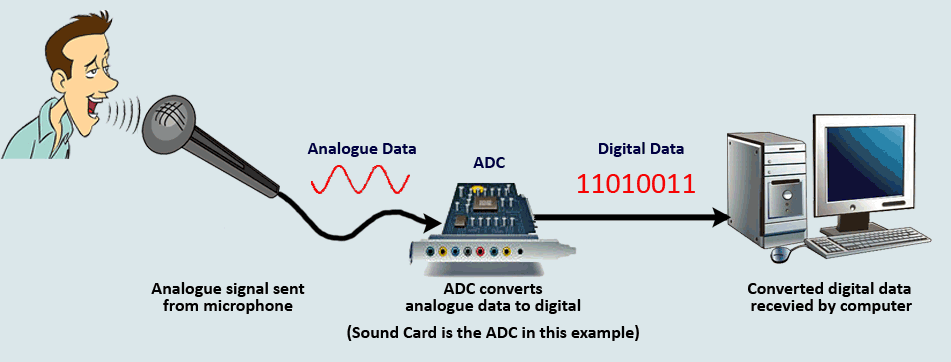
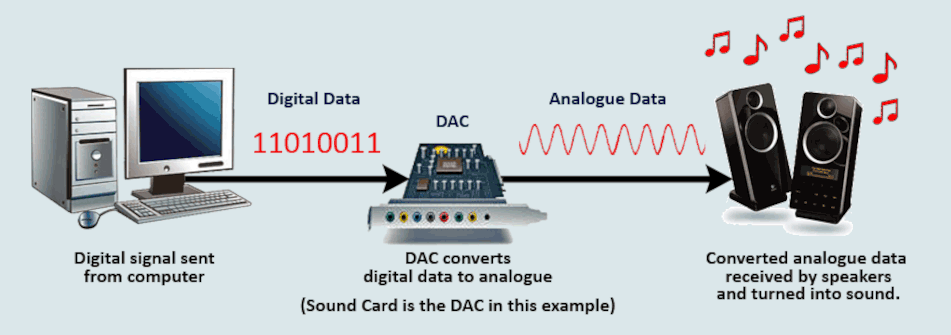
There are many different standards in use for different types of data. A few of the common ones are shown below: 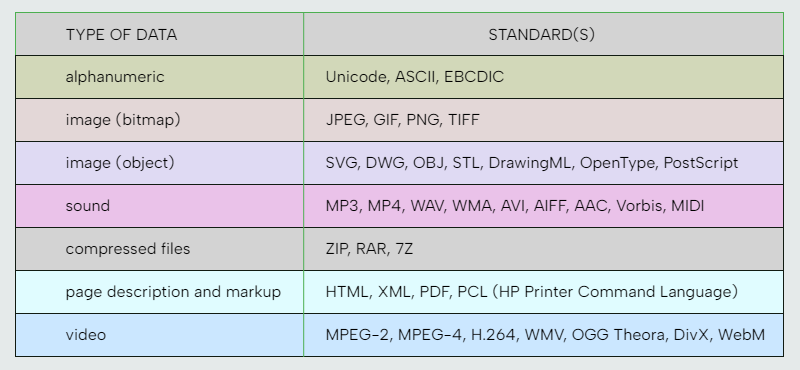
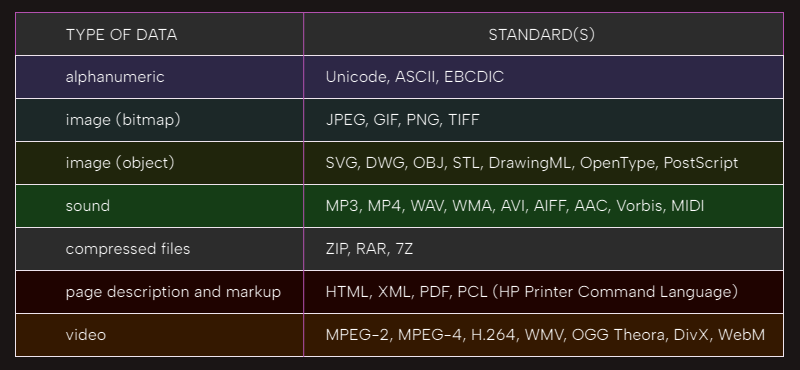
Alphanumeric character data
The data entered into the computer as characters, symbols, number digits, and punctuation are known as alphanumeric data. Since alphanumeric data must be stored and processed within the computer in binary form, each character must be translated to a corresponding binary code representation as it enters the computer. Most data output, including numbers, also exits the computer in alphanumeric form, either through printed output or as output on a display screen. Therefore, the output device must perform the same conversion in reverse. It is obviously important that the input device and the output device recognize the same code. Consistent use of the same code is required to allow later retrieval of the data, as well as for operations using data entered into the computer at different times, such as during merge operations.
Three alphanumeric codes are in common use. The three codes are known as Unicode, ASCII (American Standard Code for Information Interchange), and EBCDIC (Extended Binary Coded Decimal Interchange Code). ASCII code was originally defined as a 7-bit code, so there are only 128 entries in the ASCII table. EBCDIC is defined as an 8-bit code. Both ASCII and EBCDIC codes can be stored in a byte. Nearly everyone today uses Unicode or ASCII, though. The ASCII code was originally developed as a standard by the American National Standards Institute (ANSI). Both ASCII and EBCDIC have limitations that reflect their origins. The 256 code values that are available in an 8-bit word limit the number of possible characters severely. Both codes provide only the Latin alphabet, Arabic numerals, and standard punctuation characters that are used in English. These shortcomings led to the development of a new, mostly 16-bit, international standard, Unicode, which has supplanted ASCII and EBCDIC for alphanumeric representation in most modern systems. Unicode supports approximately a million characters, using a combination of 8-bit, 16-bit, and 32-bit words. Unicode defines three encoding methods, or Unicode Transformation Formats — UTF-8, UTF-16, and UTF-32. Unicode is multilingual in the most global sense. It defines codes for the characters of nearly every character-based alphabet of the world in modern use, as well as codes for a large set of ideographs for the Chinese, Japanese, and Korean languages, codes for a wide range of punctuation and symbols, codes for emojis, codes for many obsolete and ancient languages, and various control characters. Unicode is the standard for use on the Web and in current operating systems, including Windows, Linux, OS X, iOS, and Android.